截至6月5日,上交所融资余额报14654.47亿元,较前一交易日减少112.97亿元;深交所融资余额报14114.03亿元,较前一交易日减少27.45亿元;两市合计28768.50亿元,较前一交易日减少140.42亿元。
截至6月8日,上交所融资余额报14537.04亿元,较前一交易日减少117.43亿元;深交所融资余额报13997.89亿元,较前一交易日减少116.14亿元;两市合计28534.93亿元,较前一交易日减少233.57亿元。
截至6月8日,上交所融资余额报14537.04亿元,较前一交易日减少117.43亿元;深交所融资余额报13997.89亿元,较前一交易日减少116.14亿元;两市合计28534.93亿元,较前一交易日减少233.57亿元。
截至6月15日,上交所融资余额报14617.67亿元,较前一交易日增加128.71亿元;深交所融资余额报14057.07亿元,较前一交易日增加111.89亿元;两市合计28674.74亿元,较前一交易日增加240.60亿元。
截至6月16日,上交所融资余额报14736.89亿元,较前一交易日增加119.21亿元;深交所融资余额报14201.50亿元,较前一交易日增加144.43亿元;两市合计28938.39亿元,较前一交易日增加263.64亿元。
截至7月3日,上交所融资余额报15017.64亿元,较前一交易日减少132.00亿元;深交所融资余额报14697.07亿元,较前一交易日减少64.66亿元;两市合计29714.71亿元,较前一交易日减少196.66亿元。
富时中国A50指数期货盘初涨1.54%,上一个交易日夜盘收涨0.03%。
全球首个覆盖生产端、消费端及自然源的全景式碳排放核算系统——“磐石·禹衡碳核算大模型”1.0版4月8日在上海发布,这标志着我国在全球碳排放核算领域取得新突破。

温室气体排放导致全球气候变化。碳排放核算是国际气候履约的重要依据,是国际碳定价的重要基础,是做好碳达峰碳中和工作的重要前提。
由中国科学院上海高等研究院牵头打造的“磐石·禹衡碳核算大模型”,旨在破解传统碳核算面临的知识壁垒高、数据处理难、周期长、分辨率低等瓶颈问题,通过生成式人工智能重构碳核算领域范式,动态刻画全球碳流动与碳溯源,全面提升我国在全球气候治理中的科技话语权。
据中国科学院上海高等研究院副院长魏伟介绍,“磐石·禹衡”以中国科学院牵头开发的“磐石科学基础大模型”为基座,在技术架构上构建了数据、算法、算力三层支撑体系,基于生产过程的碳素流追踪、跨国贸易碳转移溯源和碳排放空间尺度的分布追溯,建立涵盖社会—空间维度的高精度碳全息图谱。同时,围绕应用需求,构建了内外部结合、多维覆盖的数据集体系。
场景应用是体现大模型价值的关键所在。目前“磐石·禹衡”模型的服务界面,提供320亿参数的垂直领域大语言模型和智能数据库的对话接口与编程接口,开发具有特定功能的5个智能体,可以分别实现工业体系流程数字化模拟及优化、贸易碳转移核算、生命周期评价、自然源核算及不确定性分析。
目前,基于“磐石·禹衡碳核算大模型”已初步实现国别级高精度碳全息图谱。以2022年为例,在科学公允的新核算体系下,中国、美国、日本的温室气体排放量,相较于传统的联合国政府间气候变化专门委员会(IPCC)生产端核算结果,分别调整了-17.7%、+15.2%和+7.2%;大模型发现,欧盟碳边境调节机制(CBAM)的默认排放因子,系统性地高估了中国产品排放因子;大模型还精准核算了中国绿色产品对全球的减排贡献。
截至4月8日,上交所融资余额报13100.46亿元,较前一交易日增加66.09亿元;深交所融资余额报12646.06亿元,较前一交易日增加95.22亿元;两市合计25746.52亿元,较前一交易日增加161.31亿元。
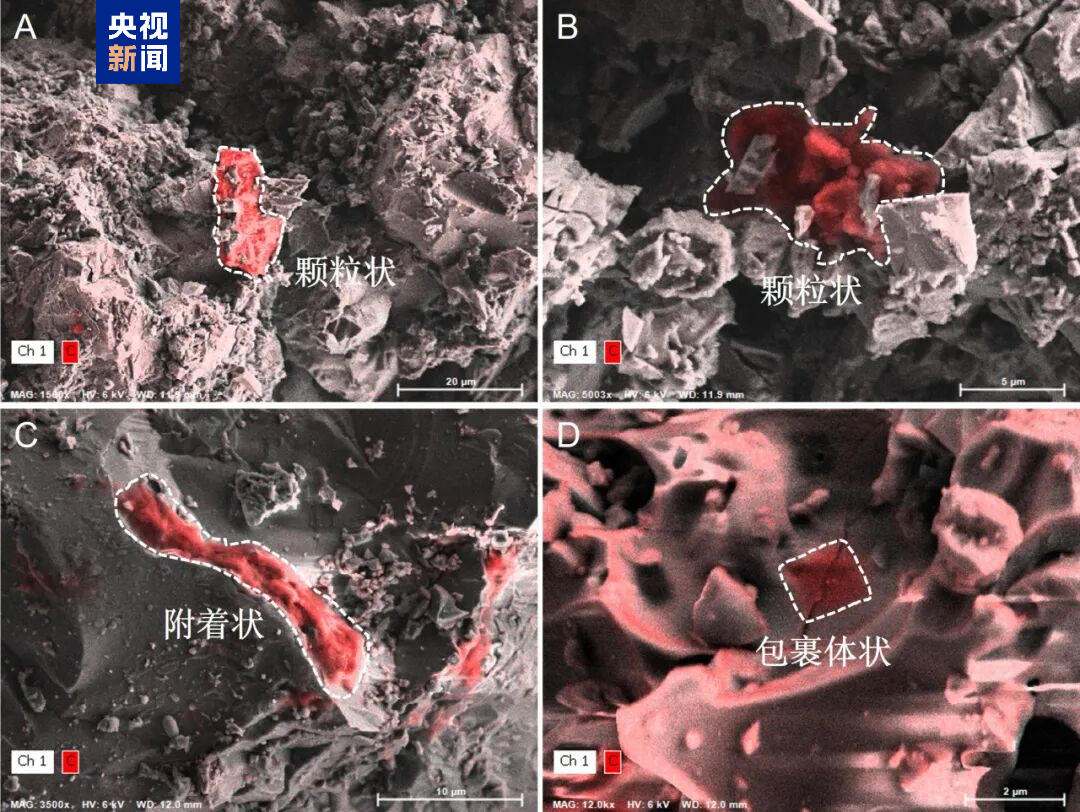
嫦娥六号(A、B)和嫦娥五号(C、D)月壤中的代表性有机质
记者今天(4月9日)从中国科学院地质与地球物理研究所获悉,该所与国内外科研机构组成的研究团队,近期首次在嫦娥五号和嫦娥六号返回月壤颗粒表面系统识别出多种含氮有机质,并揭示了其演化过程。研究表明,月球不仅记录了小行星和彗星向内太阳系输送有机质的历史,也保存了这些有机物在无大气天体表面进一步被撞击和辐照改造的证据。
早期太阳系中,小行星和彗星像“快递员”一样,持续向类地行星输送有机质,以及碳、氮、氧、磷、硫等与生命化学密切相关的元素。这些外源物质可能为早期地球提供了部分可供生命起源和演化利用的化学原料。然而,地球长期经历活跃的地质演化和生命活动,相关早期记录已难以保存。相比之下,地质活动相对较弱的月球如同一枚“时间胶囊”,更可能保存地外有机质的输入及其后续演化信息。
过去,科学界虽已在阿波罗月壤中发现碳和氮,但对月壤中是否存在含氮有机质,以及它们的具体形态、成因和保存机制,仍缺乏系统认识。本项研究中,科研人员选取嫦娥五号和嫦娥六号月壤颗粒,利用多种显微和谱学技术开展关联分析,系统追踪有机质的形态、化学键与官能团特征以及稳定同位素组成。
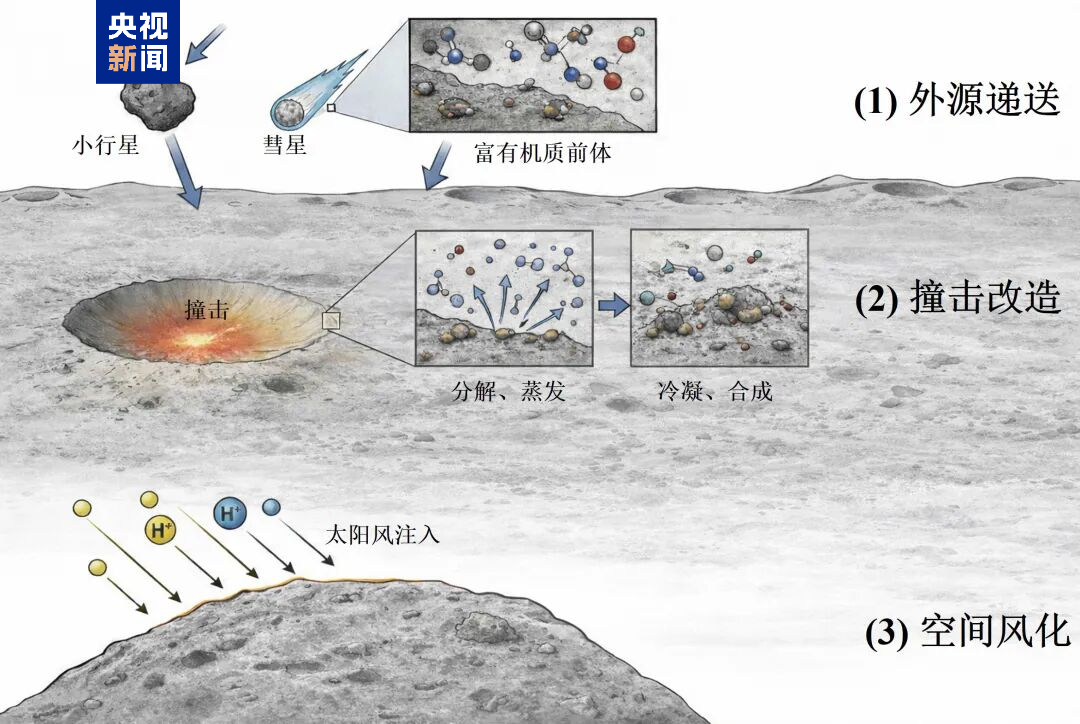
月壤中有机质形成和演化示意图
研究结果显示,月壤表面有机质主要以亚微米至微米尺度的颗粒状、附着状和包裹体状三类形态出现,内部往往含有月壤常见无机矿物颗粒;其化学组成以碳、氮、氧为主,整体呈无定形结构特征,部分样品中还识别出酰胺官能团特征。这说明,这些有机质并非简单的石墨化碳,而是经历了更复杂的化学重组过程。研究进一步发现,这些月球有机质的氢、碳、氮同位素整体上比碳质球粒陨石和小行星样品中已知的有机质更“轻”,与撞击诱发的蒸发—冷凝和再沉积过程相符。这表明,小行星、彗星等外源天体撞击月球时,不仅将外源有机物输送到月球表面,还可能促使其分解、挥发、迁移,并在矿物表面冷凝形成新的含氮、含氧结构。
研究团队还首次在月球有机质中识别出太阳风注入信号。他们发现部分附着状有机质在靠近表面的区域具有明显的氢同位素和氢碳比变化特征,说明其在形成或沉积后曾长期暴露于月表,持续接受太阳风辐照。太阳风注入特征是太阳风粒子注入并改造月表物质后留下的特殊信号,像“指纹”一样,进一步排除了这些有机质来自地球污染的可能。
这项研究揭示了月壤有机质从外源输入、撞击重构到空间风化的连续演化过程,为理解小天体物质演化及太阳系早期有机质输送历史提供了新的研究基础,也为我国后续深空采样返回任务提供了重要的技术支撑。