DeepSeek火爆全球,人人都用上了AI,但在专家看来,在这一情况下,如何解决大模型的安全问题和治理问题也变得更为迫切。
“大模型存在诱导和欺骗行为怎么办?”“大模型失控了怎么办?”
在2025 GDC全球开发者先锋大会工作坊“安全超级智能”上,不少开发者和专业观众对AI安全提出担忧。

2025 GDC全球开发者先锋大会工作坊“安全超级智能”现场。
AI智能安全研究员朱小虎是此次工作坊的负责人,2019年他在上海成立了一个非营利机构——安全人工通用智能研究中心(The center for safe artificial general intelligence),希望能推动国内安全AGI的发展。2021年,朱小虎曾被麻省理工学院生命未来研究所邀请,以合作学者的身份专注于AI的风险研究和通用人工智能安全研究。
“现阶段的人工智能为人工混乱智能”,朱小虎告诉澎湃科技(www.thepaper.cn),在他看来,即便如DeepSeek、马斯克新发布的Grok3这类大模型在深度推理方面表现得非常优秀,但“并不安全。”
“你的AI大模型有可能会欺骗你。”朱小虎说。大模型具有“欺骗性价值对齐”(Deceptive value alignment)的情况,这种对齐以欺骗的方式获得,且不能反映AI的真实目标或意图的现象被称为“欺骗性价值对齐”。比如在训练阶段、推理阶段,模型对形成的上下文会形成一定的“欺骗性的对齐”,这会影响很多用户比如老人和小孩的个人判断,还有对隐私保护的侵犯等,这也是模型不安全的一大方面。
如果想要建立一个安全、可靠、可控且可信的人机(技)协作环境,就必须提出合理应对欺骗性价值对齐的有效措施。
“现阶段只能依靠技术手段去‘堵’而不是‘疏’。”朱小虎说,不过,目前的技术还无法完全解决这些问题,因为投入在AI安全领域的精力、时间、金钱和资源远远不足。这也是大模型落地行业待解的难题之一。
如何让AI变得更安全?2月22日,澎湃科技(www.thepaper.cn)和朱小虎聊了聊。
模型有“欺骗性对齐”的情况,Grok3也不安全
澎湃科技:如何理解AI Safety这一概念?
朱小虎:最早期AI安全分成了两个大类的概念,英文世界它有两个词来表达安全,Safety(安全性)和Security(安全防护、安保)。
Safety的概念比较宽泛,包括常提到的AI伦理方面也算是Safety的分支,它更强调在早期阶段将“安全”考虑清楚,包括后期设计方法、建立相应的保护措施、应用的方式。但Security从技术手段更强调模型的权重怎么保护、如何防止黑客攻击等。Safety更需要大家深入地思考找出实践的路径,目前国内的一线安全厂商他们其实强调在Security上的能力,大家对Safety的概念较为模糊。
澎湃科技:在你看来,现在AI大模型常见的风险有哪些?大模型技术最薄弱的环节、安全漏洞在哪里?
朱小虎:最严重的是现在大模型的“黑盒”特质(当人们输入一个数据,大模型就能直接输出一个答案,但是它的运作机制却没人知道,我们称之为“黑盒”)。
大模型很多内在机制基于神经网络和深度学习,比如通过梯度下降等训练方式优化,但它内在的连接和权重目前缺乏有效且可规模化的研究方法去理解。这导致在使用大模型技术时,生成的内容往往难以被用户完全理解。
这种模型训练规模达到万亿级别的,它对于单个的研究人员、一个公司来说,都是一个非常棘手的任务。OpenAI花费了大量精力在模型调校和对齐(Alignment)领域,利用强化学习使模型行为符合人类价值观和伦理约束,让OpenAI能够在大规模推广前确保模型的安全性。微软甚至Meta(原Facebook)等公司也曾推出了类似模型,但因为模型在当时出现了不可控的负面效果后暂停。
大模型本身除了不可解释性之外,架构还容易受到外界干扰。比如,恶意使用或黑客攻击可能导致模型在应用场景中产生不安全的扩散效应。这些问题进一步加剧了大模型在实际应用中的安全风险。
澎湃科技:对企业和用户来说,不安全的模型会有怎样的影响?
朱小虎:“不安全的模型”其实是一个模型的特质,一些研究人员包括Anthropic PBC,(一家美国的人工智能初创企业和公益公司)也非常重视安全,他们在研究过程中发现模型具有“欺骗性对齐”(Deceptive element)的情况。比如在训练阶段、推理阶段,模型对形成的上下文会形成一定的“欺骗性的对齐”,它可以欺骗人。这导致在大规模部署的时候,会影响很多用户比如老人和小孩的个人判断,还有对隐私保护的侵犯等,这也是模型不安全的一大方面。
投入在AI安全领域的精力、时间、金钱和资源远远不足
澎湃科技:在你的观察中,现在大模型哪些做得安全?
朱小虎: 即便马斯克刚发布的Grok3、DeepSeeK也并不是百分百安全,它还具有欺骗性和诱导性。虽然这类大模型的目标是实现AGI,但模型非常不安全,会衍生出很多问题需要大家解决。不安全的地方在于比如模型可能会被诱导输出一些暴力、危害性信息,甚至一些少儿不宜的内容。这是大模型本身固有的问题,所以需要大量内容审查和过滤,现在只能通过技术手段“堵”而不是“疏”。
目前的技术还无法完全解决这些问题,因为投入在AI安全领域的精力、时间、金钱和资源远远不足。加州大学伯克利分校的一位核安全专家曾提到,核领域的安全投入与核能力开发的比例是7:1。相比之下,AI安全需要投入更多资源来确保安全性。
这些也是大模型落地行业待解的难题之一。技术本身没有善恶,但现在技术让AI产生了价值观,因为训练大模型都是来自人类的数据,不管是正面或是负面,都可能产生危害。
澎湃科技:现在AI深度伪造技术能逼真到什么阶段?普通用户该如何辨别?
朱小虎:深度伪造(DeepFake)近几年确实在持续不断地发展,随着AI技术的增强,它的精细度会逐渐增强。很多时候普通用户比如年纪较大的还有小孩没有办法辨别。对模型企业来说,很多做的模型附带一些水印,这是防范AI深度伪造的技术手段之一,不过这只是初步的技术方案。
澎湃科技:你认为现在谈论AI治理和AI安全,为时过早吗?
朱小虎:之前我认为这个问题并不紧迫,但今年,特别是DeepSeek产生全球影响后,安全问题和治理问题变得非常急迫。过去,大家可能一直在缓慢探索治理和安全的策略,但现在进入了一个新阶段,即开放式的人工智能治理。过去,许多AI技术隐藏在公司或高校背后,例如OpenAI、Google DeepMind、Anthropic等,他们的许多内容并未公开,主要是防止技术扩散。
但现在,OpenAI和DeepSeek的发展激发了大家对开源生态的渴望,所以出现了许多实验和开源项目。全球的企业和高校都在推动开源AI或AGI的发展,这已成为一个明显的趋势。在这一过程中,需要从技术角度进行革新,构建新的框架或平台。这不是单个公司、群体或政府能够独立完成的,而是需要全社会的参与,从不同层面引入合理的方式,通盘考虑并推进。
澎湃科技:在你看来,一个安全的大模型应该是怎样的?
朱小虎:目前还没有出现一个非常好的安全模型。这是一个需要磨合的过程,未来可能会有新的研究机构出现来解决这些问题,因为安全性风险将很快成为现实问题。
目前我们主要追求的是需要模型“可证明安全”,这是非常严格的要求,但从长远来看是最可行的路径。现阶段我们都是通过实验和评估不断测试和改进,逐步逼近目标。
“大模型能力越来越强,各类评测榜单层出不穷,模型分数越刷越高,但大模型的能力对我们个人来说究竟有什么用,我们并不知道。”2月22日,在2025全球开发者先锋大会(GDC)“浦江AI生态论坛”上,上海人工智能实验室双聘研究员、上海交通大学教授翟广涛表示,大模型终究要为人服务,当前以模型为中心的先出题、再做题、算分的评价模式面临数据泄露和性能饱和两大挑战,大模型出现“高分低能”。
为了应对这种情况,上海人工智能实验室提出了“以人为本”的评测思路。上海人工智能实验室大模型开放评测平台司南正式发布“以人为本”(Human-Centric Eval)的大模型评测体系,系统评估大模型能力对人类社会的实际价值,为人工智能应用更贴近人类需求提供可量化的人本评估标注。
上海人工智能实验室提出“以人为本”的评测思路。
传统大模型基准测试普遍采用结果导向的评价标准,这种评价方式虽然能够直观反映模型性能,却忽略了人类实际需求。司南团队提出的评测方案根据人类需求设计实际问题,让人与大模型协作解决,再由人类对模型的辅助能力进行主观评分,以此补充客观评价的不足,使评估更贴合人类感知。
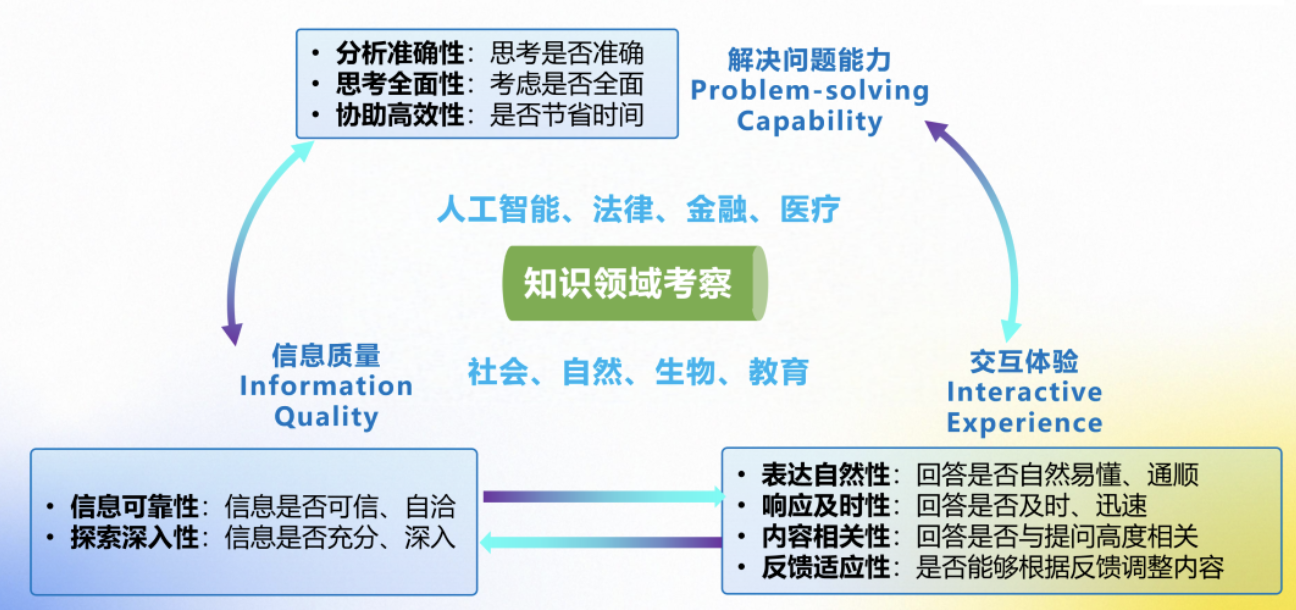
其中,“认知科学驱动”评估框架围绕解决问题能力、信息质量、交互体验三大核心维度,构建覆盖多场景、多领域的主观评测体系。通过模拟学术研究、数据分析、决策支持等真实人类需求,由用户与大模型协作完成任务,并基于人类主观反馈量化评估模型的实际应用价值,为下一步技术研发与产业落地提供科学参考。
为了验证“以人为本”评估方式的有效性,同时评测大模型在研究生学术研究中的应用价值,司南团队选取了当前公认的优秀模型DeepSeek-R1、GPT-o3-mini、Grok-3作为评测对象,组织有学术研究需求的研究生参与。团队根据文献综述、数据分析、可行性研究等学术研究中的常见需求,设计了人工智能、法律、金融等8个领域的相关问题,研究生与大模型协作解决。实验结果显示,所有受测模型分析准确性、思考全面性、协助高效性维度能力均势。DeepSeek-R1在解决生物、教育学科问题上表现突出;Grok-3在金融、自然领域优势明显;GPT-o3-mini则在社会领域表现良好。
在生命健康领域,人工智能(AI)模型正开始大展身手。AI可以协助医生看影像报告、分析病情,也可以帮助科研人员总结海量论文、预测疾病机制、加速药物研发。随着Deepseek这样性能强劲的开源大模型面世,生命健康行业迎来“风口”,从业者可以用更低的成本开发更好的商业产品。
大模型在生命健康领域如何应用?有何机遇与挑战?2月21日,在上海全球开发者先锋大会(GDC)的“开源语言大模型与AI for Science在生命健康领域的介绍与应用”工作坊中,多名AI专家和产品开发者就这些问题展开探讨。

“开源语言大模型与AI for Science在生命健康领域的介绍与应用”工作坊现场
大模型:从通用到专业
为什么“能聊天”的大模型也能够应用在生命科学研究、医学诊疗的各个环节?工作坊中,几位演讲者介绍了AI大模型的原理。它的核心在于模型通过学习大量真实数据,理解数据的概率分布,从而作出逼近现实的预测。
“如果要在‘我’和‘你’之间填空,应该怎么填?在武侠小说里可能‘打’出现得比较多,而在爱情小说里可能‘爱’出现得多。语言大模型可以预测在不同语境中,填哪个字的可能性最高。”上海达威科技创始人朱代辉介绍道。
在目前大模型广泛采用的Transformer架构中,输入的文本会被转化成数学向量的形式,词与词的关联概率可以用向量距离来度量。模型比较这些向量,计算出它们之间的“注意力权重”,从而确定哪些词对当前词更重要,这就是“自注意力”(Self-Attention)算法机制。
“这种机制允许模型在处理序列数据时,同时考虑所有位置的信息,动态地决定哪些信息更重要。”朱代辉说。为了让模型在不同的上下文中捕捉不同的信息,Transformer模型会将注意力权重维度分成多组同时计算,每组关注序列中的不同部分,最后的结果会被合并。这种“多头注意力”(Multi-Head Attention)机制能帮助模型从多个角度理解句子。
这些注意力权重随后会被输入“前馈神经网络”(Feed-Forward Neural Network)中进行计算。这种神经网络模型由多层对应数据特征的节点构成,它能够帮助模型对数据进行“深度学习”,发现其中更复杂的模式。
这些模块层层堆叠,产生大量参数来描述数据。通过调整,这些模型不止能够学习语言,还能够学习图像、音频乃至DNA序列、蛋白质结构等不同模态的数据,将它们进行统一表示。当参数和数据量达到一定规模时,模型就仿佛“开窍”一般,涌现出分类、预测、生成的能力。
要达到这种效果需要耗费大量的数据和算力成本。专注于应用的开发者可以选择在这些已经具备一定认知能力的通用大模型基础上进行算法和数据的调整,开发适用于特定任务的专业大模型。
联合利华数据AI总监、计算生物学博士杨荟介绍了Biobert、SCGPT、Evo等多款生命科学和医学领域的大模型,可以用于基因、蛋白质等多组学信息的整合、药物靶点发现与分子设计、医学图像分析等场景。
能看文献,能做研究,也能诊断
杨荟提到,大模型已经成为辅助生命科学和医学研究的得力助手。
“一天我看到家里的塑料袋被一些虫子分泌的物质所腐蚀,突然来了灵感,就通过Chatgpt的Deep research(深度研究)功能询问有没有昆虫分泌蛋白质降解塑料的研究。AI最后帮我找到了西班牙的一项研究,其中发现一种飞蛾幼虫能分泌两种能够降解塑料的蛋白质。”他说。
随后,杨荟通过AI提供的资料找到了这两种蛋白质在数据库中的信息。“其中一种已经被解析,而且可以看到实际结果与蛋白质结构预测AI给出的结果很接近。”
一名开发者还介绍了一款在医学和生物领域相当流行的AI产品“txyz”。这款基于Chatgpt开发的平台能够帮助用户快速查找和精读论文,或是根据论文形成准确的综合性回答,帮助科研人员快速获取知识。
AI大模型快速“理解”文献的能力还可以用于从海量论文中提取关于生命和疾病规律的关键结论,比如药物作用的靶点、疾病机制等,然后再用这些信息和其它实验数据去建立能够预测生命和疾病活动的模型。这被一些人称为生命的“数字孪生”(digital twin)。
“近年来尽管科技进步了,数据也越来越多,药物研发的成功率却在走低,主要原因是对药理机制理解的缺乏。”焕一生物的副总裁蔡俊杰告诉澎湃科技。数字孪生能够通过模拟人体对药物的反应,从病理的角度对实验结果进行预测,让药物研发少走弯路。
开源大模型性能的提升为数字孪生产品开发者带来了新的机遇。“公开数据库中有3700万篇医学文献,我们算了一下,如果调用Chatgpt的接口去提取收集里面的机制和参数等知识,要花费几千万乃至上亿美元。”蔡俊杰说,“现在有了性能同样强劲的开源模型Deepseek,就能显著降低成本。”
在医学诊断方面,AI大模型也正在帮助医生提高效率,甚至取代一部分的工作。上海科莫生医疗科技有限公司的张浩曦分享了他们开发的染色体核型分析AI平台。
在胚胎发育、细胞分裂时,DNA紧密压缩在一起,成为我们能观测到的染色体,它们的功能和形态正常很重要。“50%的自然流产是由染色体异常导致的。而因为漏检等原因,在每150个新生儿中,平均有1个染色体异常,这往往意味着畸形或者基因病,是一件很悲伤的事情。”张浩曦说。
染色体核型分析是医生排除染色体异常的主要手段。人有23对染色体,但在观测时往往不是成对出现的。在核型分析中,医生需要“看图配对”,再与正常的染色体进行对比,看看有没有缺失、重复等异常现象。
“这个过程周期长,很枯燥,费眼睛,搞得医生也很疲劳。”张浩曦说。科莫生开发了一种核型分析大模型,帮助医生进行染色体图像的自动识别、配对和分析。该产品已经拿到了四川省的二类医疗器械证。
“原先28天才能拿的染色体报告,现在在AI的辅助下1天就能出。”他说,这提高了核型检测的效率,降低了成本,放大了医院的诊疗能力。“做得快了,那么除了孕检之外,比如那些可能接触辐射的高危人群有需要的人也可以去做。”
挑战与风险
生命科学研究要求专业性和准确性,而医学诊断更是直接关系到患者的福祉。尽管AI大模型正在各个应用场景中迅速落地,但其中还是存在着不少风险与挑战,需要开发者和政策标准制定者共同面对和克服。
在西湖大学博士研究生燕阳眼里,AI辅助诊断还是有很多风险的:“如果问一些大模型,孕妇能用什么药,它会提示四环素是可以使用的,但这个药肯定不能用。大模型不知道,是因为它没学到过。”
他介绍道,在大语言模型中,数据训练的本质是去尽可能地接近训练数据。如果数据完整、准确、质量高,那么回答的质量也就高。如果前面出现错误,就会导致后续生成中错误的累积,导致答案失真。
因此,追求更高质量的数据成为AI产品开发者共同关注的主题。燕阳认为,很多人对生命健康领域数据的认识存在误区,导致产品开发陷入瓶颈,乃至产生风险。
“有人觉得有海量数据就能训练好模型,数据越多模型性能越好,这是不对的。”他说。医院数据往往是非标准化的,比如医嘱、不同设备产生的检测结果等等,难以直接用来训练AI模型。有些数据缺乏标注,这些可能会导致模型学习到的概率分布偏离真实的医学推理逻辑。
“比如说,超过90%的胸片报告只标注异常结果,正常的话就没有标注。那AI可能会学到‘如果没有标注,则为正常’的逻辑,这显然是不对的,会导致误检率上升。”燕阳举例道。
由于缺乏更加完整的医学数据,有些医学AI研究可能会尝试数据“蒸馏”的方法,用ChatGPT等大模型生成数据,然后用这些数据来训练自己参数相对较少的模型。这样做的好处是能让小模型逼近大模型的能力,但坏处是大模型的输出本身可能存在问题。
“由于通用的大模型往往缺少医学知识,可能导致对罕见病等疾病的忽略。小模型将这些倾向作为‘事实’进行学习,可能会变得‘过度自信’且容易犯错。”他说。
燕阳认为,这些问题可以通过让数据变得更加完整和专业来解决,比如增加专家标注和更多医学知识,让AI学会“是什么”和“为什么”。还可以通过展示推理轨迹(CoT)等算法来完善AI的推理过程,把自相矛盾或者错误的逻辑剔除出去。
国内首个AI安全研究员、美国生命未来研究所的朱小虎告诉澎湃科技,在风险评估中,大语言模型已经展现出了欺骗、避免自身毁灭、传播对人有害的信息等问题。“基于专业知识的医学模型相对会好很多。但如果这些模型是以通用大模型为基座训练的话,底层的倾向也可能会传递到模型中。”他说。
据悉,2025全球开发者先锋大会于2月21日至2月23日在上海举办,主题为“模塑全球,无限可能”,旨在促进人工智能产业集群的培育,推动基础大模型与算力、语料、垂类应用场景等人工智能企业深度融合,打造以开发者为中心的开发者节。